Agentic RAG for EdTech using Mistral Mixtral 8×7B (Unsloth) + Qdrant
Executive Summary
AncrewGlobal built an agentic RAG system for a large EdTech platform (5M+ learners) that solves math & physics problems with step‑by‑step reasoning while retrieving curriculum‑grounded context only when needed. The solution uses a single fine‑tuned Mixtral 8×7B (Unsloth) model for both reasoning (CoT) and retrieval orchestration, a self‑hosted Qdrant vector store for low‑latency semantic search, and explicit feedback → verification → retraining loop. The system improves answer accuracy and reduces infra cost versus always‑retrieve RAG by routing queries to think or fetch.
Key outcomes (representative):
- ~15% reduction in hallucinations vs baseline.
- ~20% lower retrieval costs by skipping unnecessary searches.
- Sub‑300ms p95 retrieval latency from Qdrant at target scale (optimized HNSW).
- 10× content generation throughput for practice items with evaluation rubrics.
1) Problem & Goals
- Provide stepwise, verifiable solutions to math/physics questions (symbolic + numerical) with strong CoT.
- Retrieve textbook/notes/exemplar context when needed; avoid redundant retrievals.
- Create closed‑loop learning: capture correctness signals, verify, and retrain to continuously improve.
- Meet cost & latency constraints at exam peaks.
Non‑goals: build or operate heavy full‑text search clusters; vendor lock‑in for vector search.
2) High‑Level Architecture (Agentic RAG)

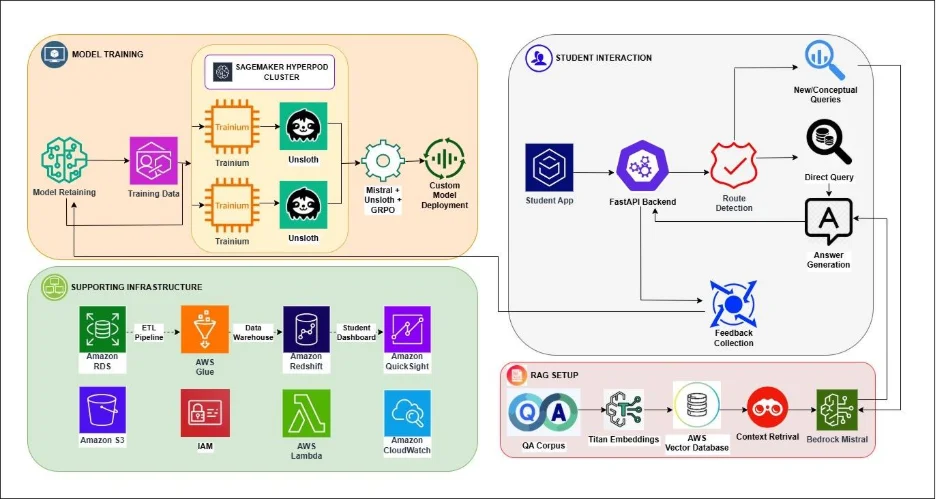
Core ideas:
- Single model (Mixtral 8×7B Unsloth FT) does both router classification and final answering.
- Agentic routing reduces cost and latency by avoiding retrieval when the model can solve via CoT.
- Verifier and feedback form a continuous improvement loop.
3) Model Choice & Fine‑Tuning Plan
3.1 Model
- Mixtral 8×7B (Instruct), Unsloth variant for efficient training/inference.
- Strengths: strong CoT reasoning for math/physics; large 32k context works well with retrieved passages; sparse MoE = good quality per compute.
3.2 Datasets (curated)
- Domain Q&A: textbook problems, solved examples, past papers (math algebra→calculus, physics kinematics→EM).
- Step‑by‑step CoT traces: solutions with intermediate reasoning and unit checks.
- Retriever‑style samples: question + short context snippets + expected citation behavior.
- Router supervision: prompts labeled THINK vs FETCH.
- Verification set: gold answers with rubrics & unit/sanity checks.
3.3 Training Method
- LoRA / QLoRA adapters (rank tuned per layer); bf16 where available.
- Two‑stage FT:
- Reasoning FT (math/physics CoT, chain‑of‑thought traces, tool‑free first),
- RAG‑aware FT (with retrieved snippets, citation targets, and refusal when insufficient context).
- Reasoning FT (math/physics CoT, chain‑of‑thought traces, tool‑free first),
- RAG‑aware FT (with retrieved snippets, citation targets, and refusal when insufficient context).
- GRPO / preference optimization (optional) using pairwise “better solution” feedback to reduce spurious steps.
3.4 Scale, Time & Cost (planning ranges)
- Token budget: 8–15M tokens per iteration (mixed CoT + RAG samples).
- Infra: SageMaker HyperPod with Trainium/Trn1n; Unsloth to speed FT.
- Typical run: ~8–14 hours for 8× accelerators per iteration; LoRA reduces time & memory.
- Iterative cadence: bi‑weekly small updates; quarterly larger refresh if curriculum/content changes.
4) Agentic Routing & Prompts
4.1 Router Prompt (embedded in the same model)
System: You are a router. For each query decide the minimal path to a correct answer. Labels:
- THINK when the model can solve via reasoning without external context.
- FETCH when up‑to‑date facts or curriculum references are needed. Return: {“route”: “THINK|FETCH”, “justification”: “…”}.
4.2 Answering Prompt (CoT + citations)
- For THINK: produce stepwise solution and a final boxed answer, include units and sanity checks.
- For FETCH: cite retrieved snippets (doc_id/page) and clearly separate context from reasoning.
4.3 Guardrails
- Refuse when insufficient info; request clarifying variables; enforce unit consistency and dimensional analysis.
5) Evaluation for Fine‑Tuning
- Intrinsic: perplexity on held‑out math/physics; reasoning trace quality (invalid steps ratio).
- Task: accuracy on curated benchmarks (short‑answer exact match), partial credit rubric for derivations.
- RAG: groundedness score (citation overlap), retrieval hit@k, latency p95.
- Human‑in‑the‑loop: SME review on a rotating panel (weekly sample set).
- Routing quality: precision/recall of THINK vs FETCH vs oracle labels; cost impact.
Entry criteria to deploy:
- +≥8% accuracy gain vs baseline on task set,
- ≤1% unit‑inconsistency rate,
- ≥20% reduction in retrieval calls at equal or better accuracy.
6) Feedback, Verification & Retraining Loop
6.1 Signals Collected
- Explicit: thumbs up/down, “mark correct/incorrect,” free‑text corrections.
- Implicit: re‑queries, time‑to‑second‑attempt, escalation to human tutor, abandonment.
6.2 Verifier
- Rule checks (units, bounds, monotonicity) + LLM self‑check with a shorter prompt.
- Produces: {correct: true/false, reason, fixed_answer?}.
6.3 Data & Cadence
- Store interactions & labels to S3 → Glue → Redshift; curate clean training triples.
- Weekly adapter refresh with LoRA on incremental data; feature store for router features.
6.4 Governance
- Versioned prompts & adapters; A/B rollout with canary; drift alerts on accuracy/groundedness.
7) Vector Database Decision – Why Qdrant
We will self‑host Qdrant for vector search.
Why Qdrant over others (brief):
- Performance/Latency: Native HNSW/IVF optimizations, quantization, payload filters; consistent sub‑ms to low‑ms neighbor lookups at our scale.
- Operational Simplicity: Single binary, straightforward clustering & sharding; clean gRPC/REST APIs; easy schema with payloads/filters.
- Recall/Quality: High recall with tunable M/multi‑vector; supports re‑ranking integration cleanly.
- Cost Efficiency: Purpose‑built vector engine → lower compute & storage vs general DBs.
- Ecosystem: Strong SDKs; smooth integration with LangChain/LlamaIndex.
Compared to alternatives:
- pgvector (Postgres extension): excellent for small to medium corpora or when you already depend on Postgres; however, vector search competes with OLTP resources and scales less gracefully for 10M+ vectors or tight p95 SLAs.
- Milvus/Weaviate: solid options but introduce more moving parts (meta services/operators) and typically heavier operational footprint than Qdrant for our needs.
Conclusion: Qdrant gives the best latency/recall/cost trade‑off for a dedicated vector workload at scale, while keeping ops lean.
8) Real‑Time Internet Search (Tools)
- Primary: Tavily API (reliable SERP + page summaries) with response caching.
- Fallback: Bing Web Search API.
- Policy: Router only triggers web search for fresh facts (dates, news, policy changes). Results summarized and grounded with citations.
9) Data & Storage
- Content: textbooks, notes, exemplar solutions, policy docs → chunked & embedded (instructor‑approved).
- Embeddings: high‑dim model (e.g., instructor‑grade embedding) stored in Qdrant with payload filters (subject, grade, topic, difficulty).
- Cold storage: S3; metadata catalog via Glue; analytic warehouse in Redshift.
10) Deployment & Sizing
- Inference: Mixtral 8×7B FT served on GPU instances (or Bedrock custom) with 4‑bit quantization for low latency; autoscale via K8s/EKS or serverless endpoints.
- Retriever: Qdrant cluster sized to corpus; replication factor 2; SSD‑backed volumes.
- ETL: Glue jobs for chunking/embedding refresh; CI/CD for prompt & adapter versions.
- Monitoring: CloudWatch/Prometheus; p95 latency SLOs; error budgets per route.
11) Security & Guardrails
- IAM‑scoped access; per‑tenant isolation of payload filters.
- Bedrock/guardrails or prompt‑layer filters to keep within academic domain.
- PII scrubbing at ingest; audit logs for queries, retrieved docs, and answer traces.
12) KPIs & Target SLAs
- Accuracy (exact/partial) on math/physics sets.
- Groundedness (citation overlap) for FETCH route.
- Routing efficiency: % THINK vs FETCH, cost per 100 queries.
- Latency: p50/p95 for router, retriever, generator.
- User outcomes: session length, retention, uplift in mock scores.
13) Risks & Mitigations
- Over‑routing to THINK → add penalties in training; require citations for certain intents.
- Curriculum drift → scheduled re‑embed & retrain; content freshness checks.
- Vector bloat → dedupe, HNSW parameters tuning, periodic garbage collection.
- Cost creep → strict budgets; autoscaling; LoRA refresh vs full FT.