Managing Secure Backup and Archival of Legacy Data for Tej Group Using MSP360 Backup
Name and Sector of Client:
The client Tej Group is a giant in Agri-Tech and agri-business sector spanning services pan-India. Their service includes:
Environment Details
- Conducting farmer training programs focused on product usage, high-yield seed adoption, sustainable pest management, and effective crop cultivation techniques.
- Engaging in research to develop high-yield and climate-resilient crop varieties, including advancements in genetic modification.
- Preserving and sourcing native crop varieties to support agricultural diversity.
- Facilitating an organic produce marketplace to connect farmers with consumers.
- Implementing IoT-enabled solutions for real-time monitoring of crop fields.
- Collecting and analyzing climate and geospatial data to enhance crop productivity and sustainability.
Due to the extensive scope of their business model, they handle and process large volumes of data across multiple domains.
Data Sources:
- Farmer Education Content: Includes personal details (name, age, education, PAN, Aadhaar, etc.), crop types, land size, year-over-year (YoY) and quarter-over-quarter (QoQ) ROI, historical crop records, training attendance, performance evaluations, yield improvement metrics, and customer feedback.
- Statistical and Analytical Data: Covers experimental findings on fertilizers, irrigation levels, crop varieties, genetic traits of disaster-resilient breeds, breeding records, and genomic sequencing data.
- Spatial and Satellite Datasets: Encompasses historical records of temperature, rainfall, soil health indicators, chemical composition, climate patterns, pH balance, and nutrient levels.
- Pest and Disease Monitoring Data: Tracks data on pest infestations, crop diseases, their impact on yield, and sustainable pest management solutions.
- Agricultural Market Intelligence: Involves market trends, supply chain insights, economic conditions, and regulatory compliance requirements.
- Geospatial Data: Includes remote sensing data, water levels, field boundary mapping, and geographical characteristics, used for yield optimization and farmer training.
- Sensor & Device Data Streams: Covers proprietary intellectual property (IP) and patents, along with sensor-generated data on nutrient levels, crop health, and soil moisture.
- Stakeholder Relationship Data: Manages CRM insights and stakeholder feedback.
- Research Collaboration Records: Includes information on research partnerships, funding sources, and grants for agricultural innovation.
Data Type and Volume:
The total volume of data was about 33 TB as given by the client in their inventory details, and distribution of the volume of data is given below:
- Agricultural Records (CSV, SQL): 800 GB
- Genetic Sequence Data (FASTA, GenBank): 18 TB
- Spatial and Satellite Datasets (GeoJSON, GML, imagery): 6 TB
- Statistical and Analytical Data (SPSS, SQLite): 5 GB
- Agricultural Market Intelligence (SQL): 250 GB
- Farmer Education Content (Images, Videos, Excel files): 5 TB
- Sensor & Device Data Streams (Avro, JSON): 120 GB
- Intellectual Property Archives (Patent XML, PDFs): 140 GB
Problem Faced by Client:
Challenges Faced with On-premises Data Storage
Backup Limitations
- The current local backup system lacks scalability, making it difficult to support the rapid expansion of agricultural data.
- Insufficient backup measures may lead to non-compliance with various Indian government regulations.
- Proper management of farmers' personal information is essential to meet India's data privacy requirements.
Risk of Data Loss
- Single Point of Failure: Relying exclusively on on-premises servers for data storage introduces a high risk of data loss due to hardware malfunctions, cyber threats, or natural disasters.
High Operational Costs
- Resource Intensive: Maintaining on-premises backup infrastructure demands substantial IT resources, including continuous hardware and software upgrades, resulting in high costs and effort.
Complex Data Recovery
- Time-Consuming Restoration: Restoring data from on-premises backups after an incident can be a lengthy and intricate process, leading to operational downtime.
Archival Challenges
Regulatory Compliance
- Meeting Legal Obligations: Adhering to data retention and archival regulations, such as Proposed Data Protection Bill (PDPB), Digital Personal Data Protection Act (DPDP), and CAP, requires strict governance and secure storage solutions.
- The Agri-Tech sector must comply with various regulations, including:
- Information Technology Act, 2000: Mandates reasonable security practices for safeguarding sensitive personal data, including farmer information.
- Data Protection Regulations: Protects personal data integrity and privacy during long-term storage while following national and international standards.
- Intellectual Property Laws: Ensures the secure storage of IP-related data, limiting access to authorized personnel only.
Data Integrity Over Time
- Risk of Corruption: Long-term storage on on-premises servers may lead to data degradation or corruption, impacting the accuracy and reliability of archived information.
Access and Retrieval Challenges
- Retrieval Complexity: Accessing archived data for audits, legal reviews, or business intelligence can be inefficient and challenging without a structured and secure management system.
Physical Security Concerns
- Protection from Environmental and Unauthorized Threats: Safeguarding archived data from physical risks such as fires, floods, or unauthorized access remains a significant concern with on-premises storage solutions.
Proposed Solution and Architecture:
To enhance data backup and archival efficiency while ensuring compliance, we propose leveraging MSP360 Backup (formerly CloudBerry) for secure storage within AWS Glacier's tiered services. This approach will incorporate well-defined roles and access policies, ensuring minimal yet controlled access to sensitive data. By utilizing AWS Glacier's cost-effective long-term storage along with MSP360's advanced management capabilities, the company can implement a scalable, secure, and regulatory-compliant data preservation strategy tailored to its specific requirements.
Architecture:
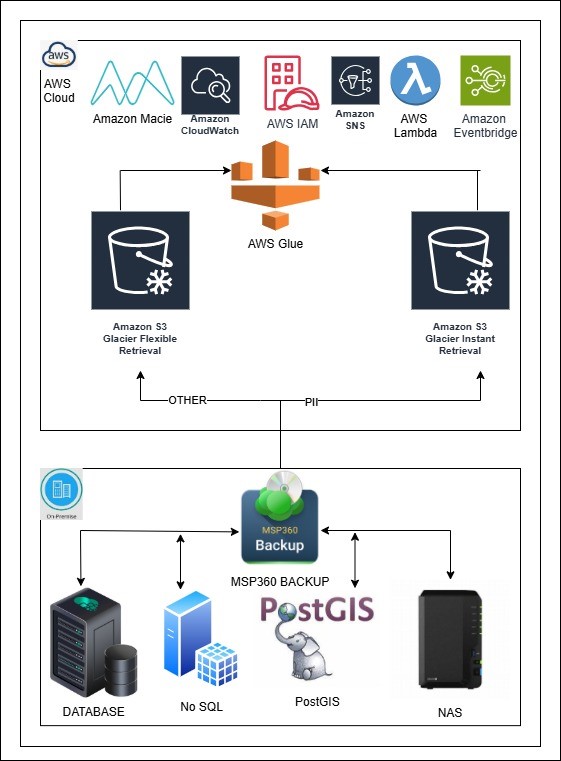
MSP360 Backup Agent and Job Setup
The client acquired the necessary licenses to facilitate data backup from their on-premises servers to the AWS S3 Glacier tier.
There were seven repositories containing diverse datasets, including agricultural records, genetic sequence data, spatial and satellite datasets, agricultural market intelligence, farmer education content, sensor & device data streams, and intellectual property archives, stored in various file formats.
To ensure efficiency, each repository was assigned a dedicated license, and parallel backup jobs were created for separate S3 Glacier buckets.
Since farmer data contained Personally Identifiable Information (PII), it was first backed up to Glacier Instant Retrieval for further processing, including masking and encryption. Once processed, the secured data was moved to Glacier Flexible Retrieval and later to Glacier Deep Archive for long-term storage.
PII Mitigation Strategy
To handle sensitive personal data, we leveraged Amazon Macie to scan CSV files and detect PII fields, such as full name, phone number, Aadhaar number, insurance details, and Kisan Credit Card number.
- Macie's findings were stored in an encrypted S3 bucket using AWS KMS encryption.
- AWS Glue was used to process data retrieved from Glacier Instant Retrieval, masking the identified PII fields before storing the sanitized dataset in S3 Glacier Tier buckets.
- The original unencrypted file was retained for compliance purposes but encrypted with KMS before storage in S3 Glacier. Once encryption was completed, the unencrypted version was securely deleted.
- For automated PII processing, an Amazon EventBridge trigger was set up to initiate a Glue workflow whenever new data is ingested into the Instant Recovery bucket.
Data Retention Policy
To comply with Indian data protection regulations such as the Digital Personal Data Protection (DPDP) Act and sector-specific policies like the Conformity Assessment Procedures (CAP) under government guidelines, retention policies were defined for each data repository.
- Agricultural Records (Personal Data):
S3 Glacier Instant Retrieval → Data Masking & Encryption → S3 Glacier Flexible Retrieval (1 year) → S3 Glacier Deep Archive (12 years) → Deletion - Genetic Sequence Data:
S3 Glacier Flexible Retrieval (5 years) → S3 Glacier Deep Archive - Statistical and Analytical Data:
S3 Glacier Flexible Retrieval (5 years) → S3 Glacier Deep Archive - Spatial and Satellite Datasets:
S3 Glacier Flexible Retrieval (20 years) → S3 Glacier Deep Archive - Agricultural Market Intelligence (SQL Data):
S3 Glacier Flexible Retrieval (5 years) → S3 Glacier Deep Archive (20 years) → Deletion - Farmer Education Content:
S3 Glacier Flexible Retrieval (5 years) → S3 Glacier Deep Archive (10 years) → Deletion - Sensor & Device Data Streams:
S3 Glacier Flexible Retrieval (1 year) → S3 Glacier Deep Archive (2 years) → Deletion - Intellectual Property Archives:
S3 Glacier Flexible Retrieval (10 years) → S3 Glacier Deep Archive
Optimized Bucket Policies for Enhanced Security
In addition to IAM-based roles and access control policies, custom bucket policies were applied to each S3 bucket to mitigate potential security risks and restrict unauthorized access. These policies ensured least-privilege access, encryption enforcement, and protection against external threats.
Outcomes and Achievements:

1. SLA Compliance and Archival Efficiency
- Through a well-defined backup strategy, performance testing, and regular validation drills, the solution consistently meets SLA requirements, ensuring reliable data retrieval times and risk mitigation standards.
2. Retrieval Time Metrics
By conducting retrieval tests and statistical analysis, we determined precise recovery times for retrieving 2TB of data:
- Glacier Instant Retrieval: 255.2 minutes (~4.3 hours) to retrieve 2TB of data
- Glacier Flexible Retrieval: 3,381 minutes (~56.4 hours) to retrieve 2TB of data
- Glacier Deep Archive (Standard Retrieval): 4,320 minutes (~72 hours) to retrieve 2TB of data
These benchmarks help in planning data recovery strategies effectively, allowing organizations to balance retrieval speed against cost when selecting the appropriate S3 storage class.
3. Cost Optimization
- By leveraging S3 Glacier Instant Retrieval instead of S3 Standard, the client achieved a 68% reduction in storage costs while maintaining faster access to critical data when required.
4. Scalable Data Storage
- With automated lifecycle policies and AWS storage tiers, the backup and archival system is highly scalable, efficiently handling the growing data volume across various agricultural operations.
5. Strengthened Security Posture
- By implementing AWS security best practices, including encryption, access controls, and threat protection, the system ensures robust data security and compliance with industry regulations.
Conclusion:
Ancrew successfully implemented a comprehensive backup and archival solution for Tej Group using MSP360 Backup and AWS Glacier services. The solution addresses all compliance requirements, ensures data security through PII masking and encryption, optimizes costs through intelligent storage tiering, and provides predictable retrieval times for business continuity planning. This scalable architecture positions Tej Group to efficiently manage their growing data volumes while maintaining regulatory compliance and operational excellence.